RST探勘影響國小學生學業成就的相關因素研究
劉威翔
國立雲林科技大學資訊管理研究所 研究生
鄭景俗
國立雲林科技大學資訊管理研究所 教授
摘要
為了瞭解影響學生學業成就的相關因素,並達到五育均衡發展的最高目標,家長與老師無不希望針對孩子在學習上的弱勢條件來進行調整或改善,然而,可能影響孩子學業成就的因素眾多,掌握這些因素藉由科學方法的驗證從而歸納出規則,作為教養的參考,並擬定教育的方針,是本研究的重要目標。
本研究以南投縣C國小於2006到2008年,總計三年的畢業學生做為研究樣本,樣本數共670筆,從學籍與輔導資料,取出 ( 1 ) 學習效能 ( Study Efficiency ) 構面:語文、數學、自然、藝術與人文、社會、健康與體育、綜合活動、日常表現的平均分數;以及 ( 2 ) 環境與背景 ( Environment and Background ) 構面:家長教育程度、家長職業、家長年齡、孩子數量、本人排行、學生身分背景、導師,共2大構面15項屬性,再做資料的前處理,並以RST ( Rough Set Theory ) 方法萃取影響國小學生學業成就的相關因素,比較全部屬性與部分屬性的正確率,然後配合樸素貝氏、多層感知機、決策樹等三項資料探勘方法評估正確率。
研究初步得到以下結果:
1. RST方法進行全部屬性分析的正確率達90.24 %。
2. 萃取出影響學業成就的規則,並找出相關屬性影響力排序。
3. 本實驗法比起其他資料探勘相關方法有易於瞭解、判讀的優點。
關鍵詞:RST、樸素貝氏、多層感知機、決策樹、資料探勘
1. 前言
現今是個資訊爆炸的e化世代,隨著科技的進步與傳媒管道的多元化,生活週遭到處充滿著各式各樣的資料,只要想找,幾乎沒有找不到的!這個看似誇張的說法,也正印證了某網路廣告的台詞「什麼都有、什麼都不奇怪」,當龐大的資料被保存下來,等待著人們去查詢、應用的同時,我們似乎得捫心自問:「我是否有足夠的能力使用這些資料」、「我該如何找到想要的資訊」或「這些看似毫無關係的資料,從中是否可以釐出具有邏輯關係的資訊」,因此如何從現有的資料中取得我們所需要,甚至於萃取出隱含的資訊,進而轉化為知識,正是身為這個世代的人們必須要學會的技能。
資料探勘是近年來逐漸獲得重視的技術,張云濤、龔玲 ( 2007 ) 認為資料探勘就是從大量的、不完全的、有雜訊的、模糊的、隨機的實際應用資料中,發現隱含的、規律性的、人們事先未知的,但又是潛在有用的,並且最終可理解的資訊與知識的非平凡過程,而且,所探勘出的資訊越是出乎意外,就可能越有價值。
由於學生在進入國小就讀的同時,學校隨即就會對其進行學籍與輔導資料的建檔,這樣的過程會持續到畢業,因此學生在六年內的資料是很完整的,但可惜的是這些資料在未經整理之前,僅僅只是龐大的個人化記錄,除了單純查閱個人的相關內容,實在很難從中得到其他共通的資訊或具邏輯性的規則,為了能讓校內存放的這些學生資料可以發揮最大的貢獻,因此本研究結合資料探勘中的RST方法來做資訊的萃取。
另外,學生在各學科的學習效能和環境與背景對其學業成就的影響,到底哪些具有不容忽視的影響力是值得關注的問題。因此,依據個案C國小自學生入學後直到畢業,在學籍與輔導資料的完整記錄,本研究進行的主要目的如下:
1. 以過去的相關文獻,了解學界關於學業成就評量的探討,建議一套實驗模式,以期有效找出規則,或提供將來能進一步以相同的實驗模式進行更多面向、更多影響因素的分析。
2. 以科學的方法取得學生學業成就的規則,分析影響學業成就的因素,並從中找出影響力較大者,提供
3. 為瞭解除了學習效能之外,環境與背景對於學生學業成就的影響為何。
4. 釐清目前國小階段「明星教師」、「家庭相關因素」是否為影響孩子學習的重要因素。
5. 提供教育單位分析在德、智、體、群、美五育中,有哪些學科在教學及評量方面,是現行教育環境下相對較弱的環節,以作為調整或改進的參考。
2. 文獻探討
本章主要探討文獻內容為學業成就的影響因素,以及本研究所涉及的資料探勘技術:屬性選取 ( Feature Selection ) 、粗集理論 ( Rough Set
Theory ) 、樸素貝氏 ( Naive Bayes ) 、多層感知機 ( Multi-Layer Perceptron ) 及決策樹 ( Decision
Tree )。
2.1 學業成就的影響因素
國內學者張春興 ( 民
78 ) 認為成就 ( Achievement ) 有以下三項意涵:一指個人或團體行動之後,能夠成功地達到所欲追求的目標。二指在某種領域 ( 如某一門學問 ) 達到某種成功的水準 ( 如獲獎 ) 或程度 ( 如得學位
) 。三指在學業成就測驗或職業成就上得到的分數。由此來看,學業成就可說是透過學習歷程所得之行為結果。而用來測量學生學業成就的科學工具,稱之為成就測驗
( 簡茂發,民 76 ) 。學科成就測驗 ( Academic Achievement Test ) ,亦屬心理測驗之一,通常用於學科教學之後,其目的在於評量學生學習後所達到的成就水準。本研究所稱之學業成就係指學生在國小畢業時的畢業總成績等第而言,即以個案於2006年至2008年三年內的畢業生之畢業總成績等第做為學業成就的依據。
歸納國內外學者的研究發現,影響學業成就的因素眾多,且多涉及心理層面,礙於人力因素,本研究初步僅以學習效能、環境與背景這2大構面,並自個案校內之學籍與輔導資料中選取共計15項屬性資料,作為探討學業成就影響因素的研究素材,相關論述如下表列所示。
表 1 影響學業成就的因素彙整
|
個人 |
個人方面 |
心理面: 智力、自我概念、成就 動機、適應、焦慮、學習習慣與態度、認知方式 |
|
生理面: 生理上的缺陷、一般性健康狀況 |
||
|
環境 |
家庭方面 |
家庭經濟、父母的社會地位、父母的教育程度、家庭氣氛、 親子關係等、家庭結構、父母親的管教方式 |
|
學校方面 |
學習環境、教學方法及內容、教師的人格特質、期望和師生互動的關係 |
|
|
社會方面 |
社會結構、文化以及經濟結構 |
資料來源:本研究整理
表 2 選取的屬性與影響學業成就的相關因素之研究
|
研究者 |
研究主要論述與發現 |
|
田慧生、孫智昌、馬延偉、陳琴 ( 2007 ) |
在國外,由國家在宏觀層面調查學生學業成就現狀並進行影響因素分析的方式有兩種,第一種是本國自己定期組織不同年齡段 ( 9、13歲或15、17歲 ) 各學科 ( 閱讀、寫作、數學、科學、公民、社會學、文學、藝術、音樂、職業發展等 ) 的學生學業成就調查,建立國家常模,開展縱向和橫向比較研究。美國的全國教育進展評議中心( NAEP ) 調查,英國的學生成績評估組織 ( APU ) 調查,日本國立教育政策研究所組織的調查,澳大利亞、紐西蘭、瑞士等國的周期性國家常模修訂調查等皆屬此類。第二種是參與國際教育成就評價協會 ( IEA ) 和經濟合作與發展組織 ( OECD ) 等組織的國際學生學業成就調查研究。目前,全世界參加上述組織的國家和地區均有幾十個之多。總的來看,第一種往往受第二種的顯著影響。 |
|
Peng、Wright ( 1994 ) |
家長的教育程度和家庭的收入確實與子女的學業成就有絕對的相關性。 |
|
譚康榮 ( 2004 ) |
父母教育程度對學生學習成就的影響,比貧富差距對學習成就的影響更為重要。 |
|
Bernstein ( 1977 ) |
階級的不同,家庭形態便有差異,而出生較低階級地位家庭的學生在面對學校教育時便發生相對劣勢的現象。 |
|
林枝旺 ( 2005 ) |
所謂家庭社經地位,其內涵包括父母教育程度,以及父母職業等四項。多數研究均指出,家庭社經地位對子女教育成就具有顯著正面影響。 |
|
謝孟穎 ( 2002 ) |
家長社經背景與學生學業成就具有密切的關聯性。 |
|
Ho Sui-Chu、 Willms ( 1996 ) |
高社經地位的家庭,有關教育事項的親子活動較多,有利於提高子女學業成績。 |
|
( 2002 ) |
子女數四個以上者,對子女的教育期望最低,子女數只有一個或二個的家長,教育期望較高,惟家庭的子女數與家長對子女教育期望未達顯著差異。 |
|
Shulman、Mosak ( 1988 ) |
父母對子女的教育期望與教養方式、教育期望可能會因為子女的出生序而有差異。 |
|
王鐘和 ( 1993 ) |
生親家庭的子女其國語、數學、和智育的表現顯著優於單親和繼親家庭的子女,而單親、繼親家庭的子女在這三項的成就則無顯著差異。控制後,生親子女的國語、數學成績仍優於單親子女,而智育的表現以單親子女最差。 |
|
Coleman ( 1988 ) |
父母的時間精力有限,子女人數越多,則每位子女獲得父母的關心與幫助( 即社會資本 )越少,進而影響其學業表現。 |
|
Powell、Steelman ( 1990 ) |
長子女或獨生子女一開始可獨享家庭資源,所以在學業有較佳的表現。一般而言出生序越後面,由於其他兄弟姊妹共享資源,家庭的資源被稀釋,所以其在學業成就的表現不如長子女或獨生子女。 |
|
陳建志 ( 2000 ) |
以臺東縣原、漢族群對學童學業成績關聯作比較,所調查的對象是臺東縣國小五年級的學童,進而發現族群對於學業成就確實有影響。 |
|
王文科 ( 1991 ) |
認為影響學業成就的因素分成內在因素與外在因素,內在因素是指個體的智力、動機和人格;外在因素包含教學方法、學習團體及教師的影響。 |
資料來源:本研究整理
2.2屬性選取 ( Feature Selection )
由Liu et al.
( 1998 ) 所定義的屬性選取是「依據某一評量指標來選擇屬性子集合的一種程序」。
屬性選取的優勢在於降低複雜程度、除去不相關數據、增加學習準確,並且改進結果,對於資料在可瞭解性方面非常有效。
2.3粗集理論 ( Rough Set Theory )
粗集理論是波蘭Pawlak教授 ( 1982 ) 提出的一種決策分析工具,最初是用來處理關於不確定性、模糊性以及粗糙性資料的數學工具。該理論在不斷的發展學習後,可有效地解決資料縮減、挖掘資料相關性、估計資料顯著性、將自資料所得之決策理論一般化、資料概略分類、挖掘資料的相似或相異處、挖掘資料模型以及挖掘因果關係,特別是應用於醫療、藥理學、商業、銀行業、市場研究、工程設計、氣象學、震動分析、衝突分析、影像處理、聲音辨識、決策分析等各項領域 ( 陳利銓,2002 ) 。
2.4樸素貝氏 ( Naive Bayes )
樸素貝氏分類法,適用於己知欲分類的類別及個數的情形下來進行分類;事先告知以怎樣的方式分成幾類別,且給了一些訓練資料 ( Training Data ) 以作為往後分類的依據。此分類法主要以訓練資料,給定目標值相關屬性值,通常目標值設定為【是、否】或【有、無】等相對應的概念,從訓練資料的相關連屬性值中選取目標值 ( 林金玲,2002 ) 。
2.5多層感知機 ( Multi-Layer Perceptron, MLP )
多層感知機 ( MLP
) 又稱為倒傳遞類神經網路 ( backpropagation neural network ) ,為當前最流行的類神經網路之一。一般所要處理的問題為非線性問題,但多層的類神經網路架構是為了增加其非線性。
2.6決策樹 ( Decision Tree )
決策樹於1993年,學者Quinlan提出C4.5演算法,其理論是基於改良在1979年的ID3演算法。C4.5演算法是先建構一裸完整的決策樹,依使用者定義的錯誤預估率 ( Predicted Error Rate ) ,來作為每一個內部節點的修剪基準 (
丁一賢、陳牧言,2005 ) 。
3.研究方法
本研究以國小學生的畢業成績作為學業成就的結果,另由學籍與輔導資料中取出共計2大構面15項屬性,再以所提出的演算法分析學習國小學生畢業成績獲得的規則,以利將來能進一步進行分析預測,提供有效的教學、輔導資訊。
表 3 國小學生學業成就因素構面、屬性
|
構面 |
屬性 |
|
學習效能 ( Study
Efficiency ) |
語文平均 (
LANGUAGEavg ) |
|
數學平均 (
MATHavg ) |
|
|
自然平均 (
SCIENCEavg ) |
|
|
藝術與人文平均 (
ARTSavg ) |
|
|
社會平均 (
SOCIALavg ) |
|
|
健康與體育平均 (
PHYSICALavg ) |
|
|
綜合活動平均 (
INTEGRATIVEavg ) |
|
|
日常表現平均 (
BEHAVIORavg ) |
|
|
環境與背景 ( Environment and
Background ) |
家長教育程度 (
PARedu ) |
|
家長職業 (
PARjob ) |
|
|
家長年齡 (
PARage ) |
|
|
孩子數量 (
CHInumber ) |
|
|
本人排行 (
SELFrank ) |
|
|
學生身份背景 (
STUDbackground ) |
|
|
導師 (
TEACHER ) |
資料來源:本研究整理
3.1研究模式
研究模式流程,共分為三個階段,8步驟進行,如下圖所示。
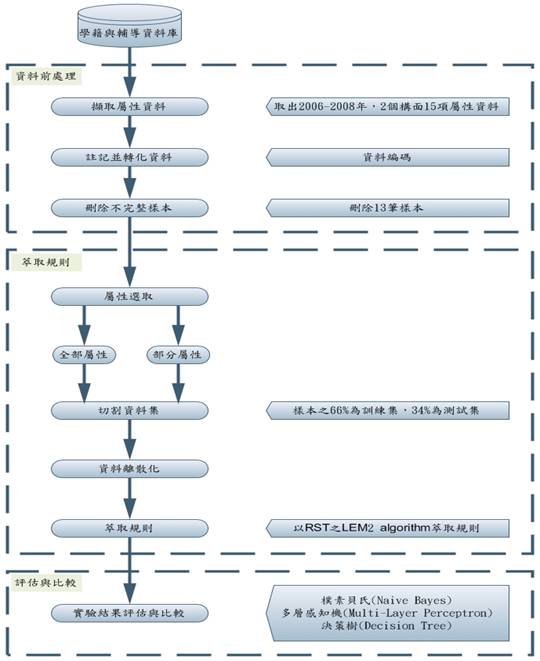
圖 1 研究模式
資料來源:本研究整理
3.2演算流程與步驟
本實驗共有三個演算階段,階段分別為一、資料前處理;二、萃取規則;三、評估與比較,本小節將針對這三個階段,說明其中的實驗進行步驟,詳細內容如下所列:
階段一:資料前處理
此階段在於擷取可能影響國小學生學業成就的相關屬性,以及將所有已收集的樣本屬性資料,透過調整屬性存在的意義,使屬性更能發揮其效用,如:A.原始資料的家長出生年屬性,改為家長年齡;B.原始資料的兄弟姐妹數,改為孩子數量,這個過程意使後讀的研究規則更加明確、有意義,而在調整屬性後,必須驗證其正確率,唯正確率達80%以上時,才有使用價值。
Step 1.擷取屬性資料
根據相關文獻、教育經驗與本論文指導教授的指導,從國小自學生入學後隨即會進行建檔的學籍與輔導資料中,將可能影響國小學生學業成就的2大構面15項屬性資料取出,並由資料中擷取2006、2007、2008三年內的畢業生共683筆資料。
Step 2.註記並轉化資料
取得的資料當中,有不少項目是屬於文字型的敘述,但這樣的形式較難作演算分析,因此在進行資料的採集建檔時,需將相關屬性資料轉化為符號或數字。
Step 3.刪除不完整樣本
本研究所採集的樣本數為683筆,其中刪除記錄不全者、資料遺漏者以及因轉學而不具參考性者共13筆。,最後實際樣本數計670筆。
階段二:萃取規則
這個階段將透過RST的分析萃取出影響國小學生學業成就評量的規則,並找出相關之因素。
Step 4.屬性選取
此步驟分為兩部份進行,第一部份以所有屬性 ( 共15項 ) 進行演算的步驟;第二部份則透過
Chi Squared 、 Gain Ratio 、 Info Gain 、 Symmetrical Uncert 四個方法進行屬性選取,在剔除影響力較低的5個屬性後,進行演算。
Step 5.切割資料集
使用RSES軟體中的Split in Two將實際樣本 ( 670筆 ) 的66%切割做為訓練集資料 (
442筆 ),其餘的34%則為測試集資料 ( 228筆 ) 。
Step 6.資料離散化
切割完畢的訓練集與測試集資料,即透過RST以RSES的Global
method運算,產生屬性切割點與個別的離散化決策表,將部分原先屬於連續型的原始資料進行離散化。
Step 7.萃取規則
對訓練集資料離散化後所得的離散化決策表以LEM2 algorithm萃取規則,建立學業成就評量規則。
階段三:評估與比較
Step 8.實驗結果評估與比較
依據階段二Step 7所得到的規則數,和所計算出結果的正確率,利用測試集資料來進行分類驗證,檢視每條規則的正確率 ( Accuracy ) ,並與進行屬性選取的另一部份結果進行比較。最後,相關研究將以樸素貝氏 ( Naive Bayes ) 、多層感知機 ( Multi-Layer
Perceptron ) 及決策樹 ( Decision Tree ) 方法,對影響國小學生學業成就評量相關因素之分析的研究結果,進行評估與比較。
4.1個案資料介紹
C國小於西元1899年創設,迄今已有百年歷史,雖然這孕育下一代的搖籃曾遭逢九二一大地震的洗禮,更不幸面臨倒塌拆除的命運,然而憑著一群在這裡無私奉獻,並對教育懷抱著熱情與理想的老師們,伴隨著慈濟大愛的重建而浴火重生,如今的它依然為基礎教育盡忠職守、作育英才。
C國小在教育部的學校類型分類中屬於「智」類,現有教職員人數約80名,班級數約四十班,學生數約為一千三百餘人,於規模上屬於中大型學校,屬於地方上的中心學校,身兼指標與領導地位。
4.2個案驗證與比較
經過前置作業處理,可供分析演算的資料有670筆,來進行資料探勘技術分析與比較,詳細的演算過程呈現如下:
1. 屬性選取:本研究使用四種方法來作屬性選取與排列,並推論出可剔除的屬性為:家長職業 ( PARjob )、家長年齡 ( PARage )、孩子數量 ( CHInumber )、本人排行 ( SELFrank )、導師 ( TEACHER )。
2. 切割資料集:將原始資料集分為66%的訓練集442筆,與34%的測試集228筆。
3. 資料離散化:以相同的屬性離散化切割點,先對訓練集進行資料離散化,再對測試集進行離散化。
4. 取得規則:對經離散化後的訓練集資料,以LEM
5. 實驗結果評估與比較:
第一部份:分析全部屬性 ( 15項 ) 的規則數、正確率與標準差,可得
表 4 。
表 4 RST 實驗結果 ( 全部屬性 )
|
實驗序 |
規則數 |
正確率 ( % )
|
|
|
1 |
66 |
89.2 |
|
|
2 |
72 |
89.8 |
|
|
3 |
82 |
92.2 |
|
|
4 |
80 |
89.8 |
|
|
5 |
65 |
88.3 |
|
|
6 |
70 |
91.4 |
|
|
7 |
87 |
91.6 |
|
|
8 |
63 |
90 |
|
|
9 |
72 |
89.9 |
|
|
10 |
71 |
90.2 |
|
|
|
|||
|
平均正確率 ( %
) |
標準差 |
||
|
90.24 |
0.011155 |
||
資料來源:本研究整理
第二部份:以樸素貝氏 ( Naive Bayes ) 、多層感知機 ( Multi-Layer Perceptron ) 及決策樹 ( Decision
Tree ) 等資料探勘方法,對國小學生學業成就評量規則的相關因素做正確率的比較。所有的規則萃取方法結果,皆將十次實驗數據平均,最後發現本研究所採用的RST ( 粗集理論 ) 分析,正確率最高、標準差最小 ( 表 5 ) ,且相較於其他方法,RST能夠把所得的規則以非常詳細且易於判讀的方式作呈現,使人方便解讀分析的結果。
表 5 四種方法的比較
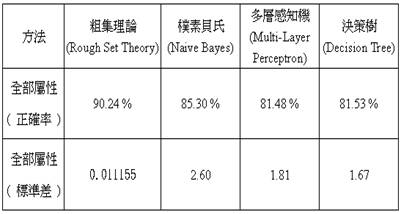
資料來源:本研究整理
5.結論
對每一等級的重要規則說明如下:
( A ) 優等規則
If ( 學生身分背景為一般 ) and ( 日常表現平均在90.0625分以上 ) and ( 語文平均在91.5375分以上 ) and ( 綜合活動平均在91.975分以上 ) Then ( 畢業總成績等第 ) 為S。
( B ) 甲等規則
If ( 自然平均在64.3分到88.6625分之間 )
and ( 學生身分背景為一般 ) and ( 語文平均在73.85分到88.9875分之間 ) and ( 健康與體育平均在81.1375分到88.2875分之間
) Then ( 畢業總成績等第 ) 為A。
( C ) 乙等規則
If ( 語文平均在58.775分到73.85分之間 )
and ( 學生身分背景為一般 ) and ( 自然平均在64.3分到88.6625分之間 ) and ( 綜合活動平均在83.625分到90.0625分之間 )
and ( 健康與體育平均在81.1375分以下 ) Then
( 畢業總成績等第 ) 為B。
( D ) 丙等規則
If ( 語文平均在58.775分以下 ) and ( 數學平均在19.325分到47.675分之間 )
and ( 自然平均在64.3分以下 ) and ( 綜合活動平均在83.625分到90.0625分之間 )
Then ( 畢業總成績等第 ) 為C。
( E ) 丁等規則
If ( 語文平均在58.775分以下 ) and ( 數學平均在19.325分以下 ) Then ( 畢業總成績等第 ) 為D。
表 6 所列為每個屬性所支持的規則數統計,以判斷該屬性是否為規則萃取的重要依據。
表 6 各屬性所支持的規則數統計
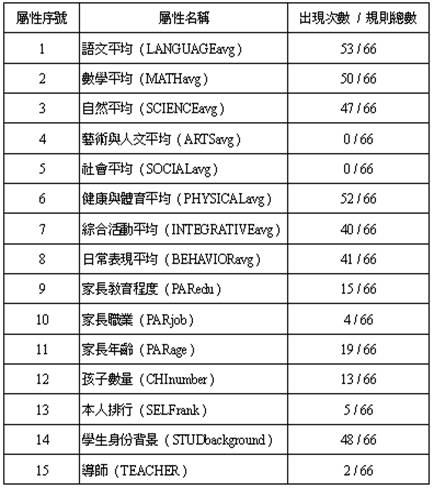
資料來源:本研究整理
1. 從摘錄的規則來進行研判,規則的支持度 ( 出現次數 / 規則總數 ) ,屬性排序為:1、6、2、14、3、8、7、11、9、12、13、10、15、4、5,其中可以看出:屬性1、2、3、6、7、8、14,在全部66條的規則中,有40條以上的規則皆與之相關,因此這些屬性是進行分類時,重要的相關因素。
2. 環境與背景構面中學生身分背景是值得注意的部份,擁有健全家庭功能的學生,確實比起其他家庭功能不完善的學生在學業成就上更容易獲得高的評價。此外,以往家長們常會在學生面臨分班時,有挑選「明星教師」的迷思,現階段於本個案研究中亦可看出,事實上,環境與背景構面中的導師屬性並沒有直接或特別影響學生學業成就的關係存在,因此,教學現場的主角還是應該回歸到學生身上,接著思考如何引導學生養成正確的讀書態度與方法,佐以良好的學習環境,並打好學習的基礎,會是比較實際的。
3. 本研究於實驗過程中發現,在國小階段,本著鼓勵學生學習,並以多元評量為理念,避免成績導向致使學生的學習觀念扭曲、功利化,老師們在學業成績的處理上,普遍有偏高的趨勢,雖然如此,並不影響以RST作為萃取學生學業成就評量規則方法的效力,所萃取出的規則,依舊可見其客觀判斷的敘述,也符合當今學者努力推行深耕語文教育的精神。
4. 本研究藉由RST得到規則,實驗分析的正確率也在所提出的相關研究法中居於最佳的地位,是以本研究認為,透過RST來分析資料並取得規則除了容易操作、方便進行外,事實能客觀呈現且易於判讀也是其優點。
參考文獻
1. 丁一賢、陳牧言,「資料探勘」, 滄海書局,136-154頁,2005。
2. 張云濤、龔玲,「資料探勘原理與技術」,五南圖書,1-9頁,2007。
3. 田慧生、孫智昌、馬延偉、陳琴,「我國學生學業成就調查立足何處」, 中國教育報,2007。
4. 陳秋婷,「一個適用於不平衡訓練資料集的多變量決策樹之研究」, 國立台南師範學院碩士論文,2002。
5. 陳家如,「學校因素對學生學業成就的影響」,國立台北大學碩士論文,2006。
6. 李豪剛,「運用資料探勘技術於臺灣鋼筋混凝土橋梁構件劣化因子之研究」, 國立中央大學碩士論文,2007。
7. 巫有鎰,「學校與非學校因素對台東縣國小學生學業成就的影響:結合教育機會均等與學校效能研究的分析模式」,國立屏東
8. 陳秋婷,「一個適用於不平衡訓練資料集的多變量決策樹之研究」,國立台南師範學院碩士論文,2002。
9. 葉怡成,「類神經網路模式應用與實作」,儒林圖書公司,2003。
10. 王進德、蕭大全,「類神經網路與模糊控制理論入門」,全華科技圖書,2003。
11. 陳家如,「學校因素對學生學業成就的影響」,國立台北大學碩士論文,2006。
12. 謝亞恆,「淺談臺灣各族群學童學業成就差異之比較」,私立南華大學碩士論文,2004。
13. 林枝旺「家庭背景因素對子女學業成就之影響」,國立嘉義大學碩士論文,2005。
14. 黃琪媚,「國中生的父母親管教方式、制握信念、學習壓力與學習成就之研究」,私立大葉大學碩士論文,2007。
15. 賴威利,「利用約略集合理論預測燒燙傷患者死亡率」,私立南台科技大學碩士論文,2005。
16. Z Pawlak, “Rough Sets.”, Informational
Journal of Information and Computer Sciences, 11:341-356, 1982.
17. Das, S., “Filters, wrappers and a
boosting-based hybrid for feature selection”, Proceedings of the Eighteenth
International Conference on Machine Learning, Williamstown, MA, 74–81, 2001.
18. Johannes Gehrke, Raghu Ramakrishnan,
Venkatesh Ganti, “Rain
Forest - A Framework for Fast Decision Tree Construction of Large Datasets.”,
Data Mining and Knowledge Discovery, 4(2/3), p127-162, 2000.
19. Liu, H., Motoda, H., “Feature Selection for
Knowledge Discovery and Data Mining” Kulwer Academic Publishers Norwell, 1998.
20.
Gang,
Ira N. and Klaus F. Zimmermann., “Is Child Like Parent? Educational Attainment
and Ethnic Origin,” Journal of Human Resourses, 35(3): 550-569, 2000.
[回本期目錄]